
Your platform for AI and data pipelines.
Dagster is a unified control plane for teams to build, scale, and observe their AI & data pipelines with confidence.









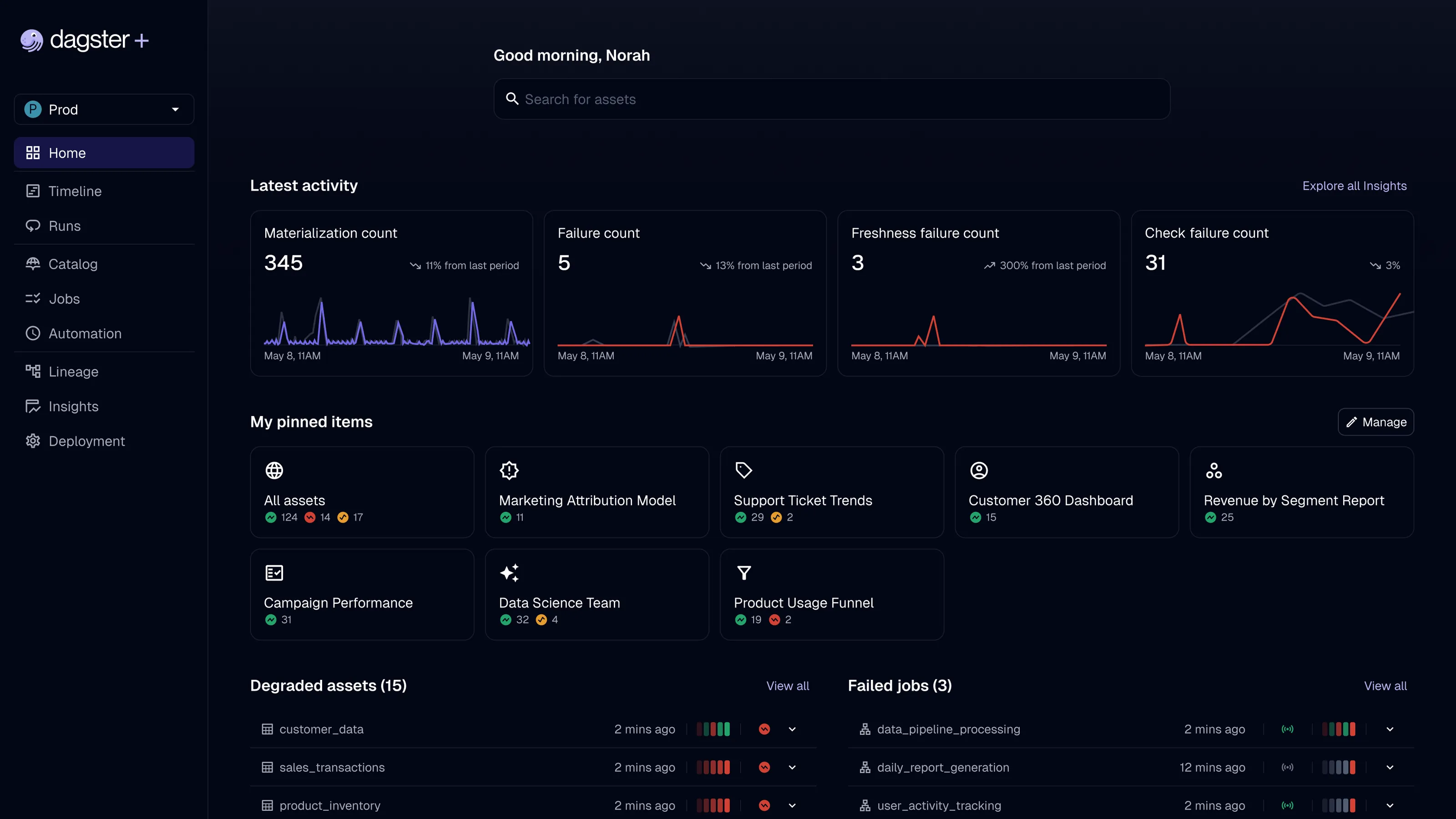
Dagster+ Summer Update
Preview new Dagster+ features including freshness and asset health monitoring, a redesigned asset catalog, and realtime insights.
Data engineering doesn't have to be a drag.
Built for modern data engineering workflows with local testing, branch deployments, and reusable components.


Dagster lets teams collaborate without sacrificing velocity. Get platform-wide visibility across teams without giving up governance and quality. Dagster is the only modern orchestrator built for high-performing teams.

Forget task-by-task tedium. Model your data assets, tables, files, ML models, notebooks, and more, and unlock a built-in catalog, lineage, and cost insights from day one.

Automatically track, document, and audit every dataset to ensure data integrity, compliance, and transparency across the entire lifecycle.
Data engineering on rails.
Integrates with any stack.
From S3 to Snowflake to PowerBI and more, Dagster's built-in integrations make it easy to unify your stack.
Built for engineers,
loved by data leaders.
An developer experience engineers love with the transparency, control, and insights data leaders need.
Self-service isn't a pipe dream.
Build reusable components so your teams can focus on business logic, not boilerplate.
Ship data and AI products faster.
Automate, monitor, and optimize your data pipelines with ease. Get started today with a free trial or book a demo to see Dagster in action.
Data Engineers can have
nice things too.
Legacy orchestrators force you to test in production.
Dagster is built from the ground-up with software engineering best practices, so you can test in any dev-stage locally.
Automatically deploy to staging environments, and ship confidently.

Identify data quality issues long before your stakeholders notice, making data cleanup jobs a thing of the past.

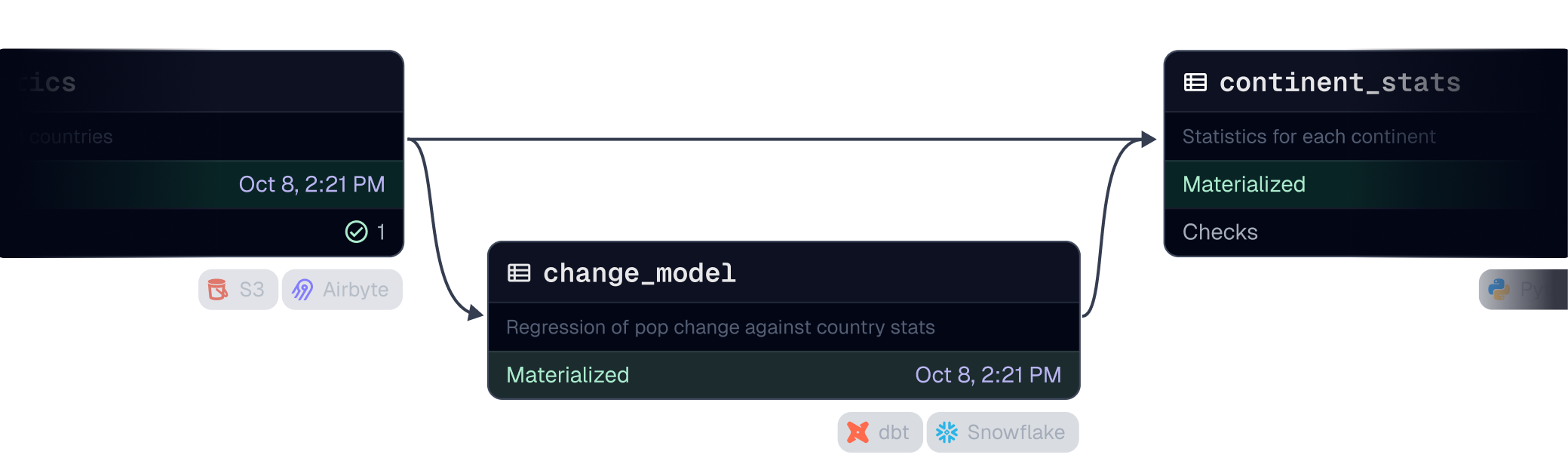
From its raw source to its final form—across every transformation, dependency, and workflow, whether it came from a database, an API, a file, or another process.
End-to-end cost insights
Full data & column-level lineage
Custom metadata

Dagster doesn’t just track whether a task ran—it tracks metadata about the data itself and provides source observability so you always know:
What data exists?
(What columns and types exist in this dataset?)Where did it come from?
(Did this come from Snowflake, an API? etc.)Is it fresh, complete, and trustworthy?
(When was it last updated?)


